OpenAI killed a consumer video app to save compute for ChatGPT. Intel and AMD CPU supply tightened just as memory stayed constrained. Google Research pushed extreme compression to run frontier-scale behavior on cheaper hardware. Databricks turned SIEM into “just another lakehouse workload” and wired agents directly into security operations. Kleiner Perkins raised $3.5B to underwrite the next wave of AI-native companies.
The connective tissue isn’t “AI progress.” It’s a repricing of infrastructure constraints and a reshaping of who owns the margin stack.
Compute is no longer a background assumption, it’s the primary product manager. Capital is moving accordingly, from generalist venture into infra-heavy, workflow-heavy bets. And the software layer is quietly re-bundling around data gravity and agentic surfaces, not around traditional app categories.
If your 2026 plan assumes “more features, more models, more usage” without a view on where your compute, data, and security surfaces actually sit in this new stack, you’re not just exposed, you’re building on someone else’s bottleneck.
BLUF
At Neue Alchemy, we support leaders navigating inflection points, when tech, capital, and policy converge. If your roadmap is already in motion and you're pressure-testing execution, we're open to conversations.
We also reserve capacity for education, SMBs, and mid-market leaders, those starting, mid-flight, or seeking outside perspective before systems harden.
INFRASTRUCTURE / COMPUTE
Compute ceilings are now the real product roadmap
OpenAI killed its standalone Sora video app to conserve compute for ChatGPT growth, per Business Insider. The decision routes GPU budget toward the assistant and core APIs instead of a new consumer video surface.
The Bet: The assistant and API ecosystem will generate more durable revenue and data than a viral video app, and are worth hard tradeoffs in user-facing innovation.
So What? This is a public admission that the constraint on frontier AI isn’t demand or ideas, it’s GPU allocation. Product surface area is now gated by infra, not imagination. If OpenAI is triaging features, every downstream builder is implicitly exposed to the same ceiling: your vendor’s capacity planning, not your own roadmap.
The Risk: If you anchor your product on a single frontier provider, their internal prioritization can strand your features, rate limits, latency, or outright deprecation. And if you’re betting on video or other heavy modalities, you’re competing directly with your vendor’s flagship products for the same compute pool.
Action: • Map your dependency on any single model vendor, by feature, by SKU, by revenue, and quantify what happens if your effective capacity is cut by 30–50%. • Stand up at least one alternative path: smaller/compressed models you can self-host for core flows, even if quality is lower. • When negotiating enterprise agreements, push for explicit capacity and latency SLOs tied to your usage, not just generic “best effort” language.
Sources say worsening supply constraints in Intel and AMD CPUs are hitting PC and server makers already dealing with a severe memory chip shortage, via Techmeme / Nikkei Asia. This is not GPUs, this is baseline x86 and DRAM/HBM.
The Bet: The industry has over-rotated to GPU scarcity in its planning, underestimating how fragile general-purpose compute and memory supply chains have become under AI demand.
So What? Your infra roadmap is now constrained at three layers: GPUs, CPUs, and memory. That changes the calculus on “just spin up more instances” and on refreshing fleets. It also makes efficiency, at the software and model level, a direct competitive weapon, not an optimization project.
The Risk: If you assume OEMs will absorb the pain, you’ll be surprised by lead times, price hikes, or silent spec downgrades. And if your architecture is chatty and wasteful, over-sharded microservices, unoptimized inference, you’ll be the first to feel the squeeze when capacity tightens.
Action: • Sit down with your OEM and cloud reps this week and get concrete: delivery timelines, allocation priority, and any upcoming pricing changes for CPU and memory-heavy SKUs. • Identify your top 3 most wasteful workloads, by CPU-hours and memory footprint, and assign owners to either replatform, compress, or defer them. • Treat infra procurement like a strategic function, not a back-office task, finance, product, and engineering should be in the same room for 2026–2027 capacity planning.
Google Research introduced TurboQuant, an “extreme compression” approach to run large models efficiently on cheaper hardware, per Google Research Blog. The work targets aggressive quantization and compression while preserving performance.
The Bet: Inference economics will be won as much by compression and clever math as by access to the latest GPU generation.
So What? The assumption that better AI always means higher infra bills is breaking. If compression like TurboQuant becomes standard, the cost curve for serving capable models drops, which opens the door for more on-prem, edge, and multi-tenant deployments without hyperscaler-scale budgets. It also means your pricing power erodes if you’re just passing through today’s high inference costs.
The Risk: If your business model bakes in current per-token or per-call costs, a competitor using compressed models on cheaper hardware can undercut you on price or margin. And if you’ve over-invested in heavyweight architectures without a path to compression, you’ll be stuck on the wrong side of the efficiency curve.
Action: • Ask your AI team, or vendors, for a concrete compression roadmap: quantization, distillation, pruning. If there isn’t one, that’s a gap. • Run a simple sensitivity analysis: what happens to your unit economics if inference costs drop 50–70% over 18–24 months? Adjust pricing and packaging assumptions accordingly. • For edge or on-prem products, start testing compressed models now, even if quality is slightly lower, to understand the trade space before your customers ask for cheaper, local options.
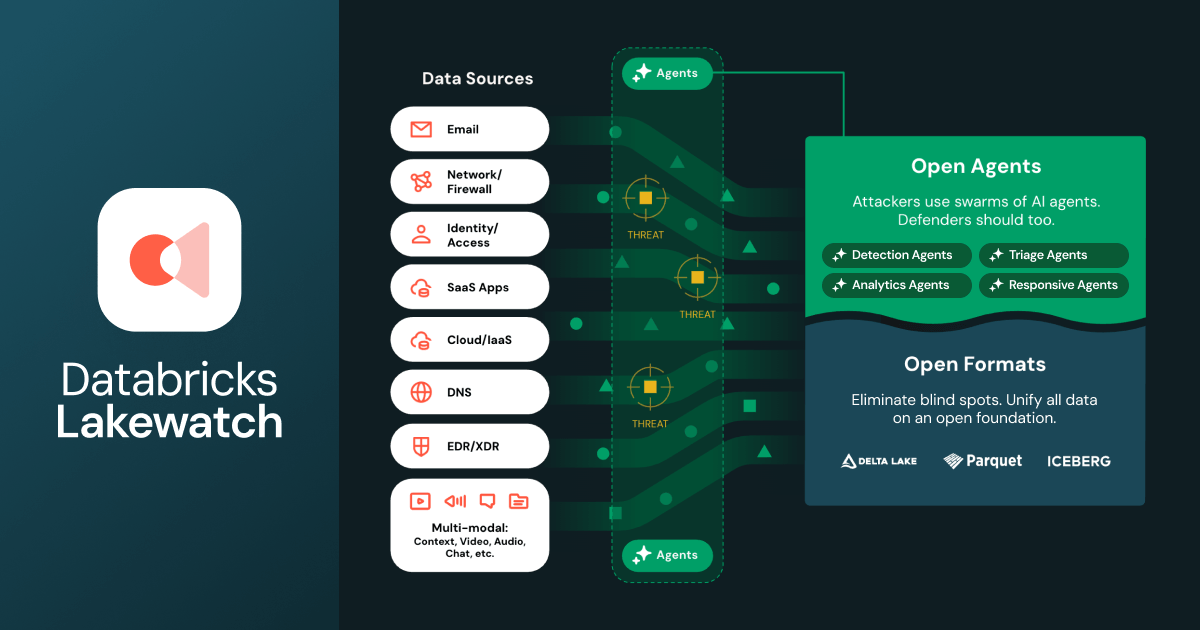
DATA / SECURITY STACK
Security is becoming just another lakehouse workload, and an agent surface
Databricks announced Lakewatch, an open, agentic SIEM built on the lakehouse, per the Databricks Blog. Security logs and telemetry are treated as standard lakehouse data, with agents operating over them for detection and response.
The Bet: SIEM doesn’t need to be a separate, closed platform, it can be a workload on your existing data stack, with agents orchestrating the work instead of humans clicking through dashboards.
So What? This collapses a long-standing boundary: security data is no longer quarantined in a proprietary SIEM silo. It lives alongside product, ops, and business data, and the same agent frameworks you’re using for analytics or ops can now act on security events. That’s a structural threat to legacy SIEM vendors and a strong pull toward consolidating on a single data plane.
The Risk: If you move security into your general data stack without discipline, you expand blast radius, a misconfigured permission now exposes both customer data and security telemetry. And if your security team isn’t ready to operate in a lakehouse world, you risk tool sprawl: half in old SIEM, half in new agents, with gaps in between.
Action: • Inventory where your security data actually lives today, SIEM, logs, data warehouse, object storage, and map duplication and blind spots. • If you’re already on Databricks or a similar lakehouse, pilot a narrow Lakewatch-style use case: one log source, one detection, one agentic response flow. Prove the pattern before you rip and replace. • Bring your CISO and data platform lead into the same planning cycle, security architecture and data architecture are now the same conversation.
Gizmodo reports Meta lost a major child safety case with a $375M verdict and thousands of similar cases queued up, per Gizmodo. The ruling reframes child safety from a policy issue to a legal liability with real damages.
The Bet: Courts are ready to treat product design and safety systems as accountable, measurable obligations, not just best-effort moderation.
So What? Trust & safety is now a line item on your legal risk model. For any product touching minors, directly or via mixed-age platforms, you will be asked to show not just policies, but evidence: logs, models, interventions, and their effectiveness. That pushes safety into the same category as security and privacy: auditable, testable, and budgeted.
The Risk: If you treat safety as an afterthought or outsource it entirely to vendors, you’ll have no defensible story when regulators or plaintiffs ask, “What did you know, when, and what did you do?” And if your AI features increase engagement without proportional safety controls, you’re compounding risk.
Action: • Identify every surface where minors can plausibly be users or collateral participants, sign-up flows, sharing, recommendations, AI-generated content. • Stand up a basic “safety evidence” pack: metrics, interventions, review processes, and model behavior tests you can show to regulators, partners, or courts. • For new AI-driven features, add a safety design review gate, with veto power, alongside security and privacy review.

CAPITAL FLOWS
Capital is arming infra-heavy and workflow-heavy plays, not just model labs
Kleiner Perkins raised $3.5B across AI-focused funds, $1B for early-stage and $2.5B for growth, per Crunchbase News. The mandate is explicitly AI, with capital ready to follow companies from seed through late-stage.
The Bet: There is enough real AI revenue, and enough room for new category leaders, to deploy multi-billion-dollar funds without relying on quick flips or hype.
So What? Late-stage capital is back for AI, but it’s not funding science projects. It’s looking for companies that own a wedge: infra (compute, data, security) or deep workflow (vertical SaaS with AI-native cores). That raises the bar for “AI startup”, you need traction, not just a model demo, to compete for this money. It also means incumbents will face better-funded challengers in specific workflows they’ve treated as “nice to have” features.
The Risk: If you’re an early AI startup with some traction, you risk over-raising into a market that still hasn’t fully normalized pricing, locking in expectations you can’t meet. If you’re an incumbent, you risk underestimating how quickly a well-funded AI-native competitor can build a full-stack alternative to one of your “adjacent” products.
Action: • As a founder, tighten your story around one of two things: owning a critical layer of the AI stack, or owning a mission-critical workflow where AI is the engine, not the add-on. • As an incumbent operator, map where AI-native startups are already nibbling at your edges, especially in data-heavy, decision-heavy workflows, and assume they’ll have access to $50–200M growth rounds. • If you’re raising, be explicit about capital efficiency and path to profitability, the presence of big funds doesn’t mean a return to 2021 burn patterns.
Ex-Houlihan Lokey tech bankers launched a digital infrastructure fund targeting data centers, fiber, and towers, per Bloomberg. These are restructuring specialists moving into owning the assets.
The Bet: AI-driven demand will push digital infra into a leverage and consolidation cycle, with distressed assets and pricing power opportunities for sophisticated capital.
So What? Your “cloud” is someone else’s balance sheet. As infra assets consolidate under specialized funds, expect more active management of pricing, utilization, and contract terms. For operators, that means less room to assume flat or declining infra costs over multi-year horizons, and more volatility if your workloads are tied to specific regions or facilities.
The Risk: If your architecture is tightly coupled to a specific colo, data center operator, or region, a change of ownership can translate into surprise cost increases or contract renegotiations. And if you’re a smaller infra provider, you may find yourself competing with capital structures optimized for scale and leverage you can’t match.
Action: • Ask your cloud and colo providers about their underlying ownership and financing, know who actually owns the buildings and fiber your workloads depend on. • For large, predictable workloads, explore longer-term contracts or reserved capacity to lock in pricing before consolidation-driven repricing hits. • If you’re an infra startup, assume your exit paths now include infra funds, design your metrics and contracts to be legible to that buyer set.

GEOPOLITICS / SOVEREIGNTY
AI is now regulated like hard infrastructure, chips, cloud, and exits
Sources say China barred Manus co-founders Xiao Hong and Ji Yichao from leaving the country while it reviews whether Meta’s $2B acquisition of Manus violates foreign direct investment rules, via Techmeme / Financial Times. The deal is being treated as an FDI and national interest issue, not just a tech M&A.
The Bet: Agentic AI and core algorithmic IP are strategic assets on par with semiconductors and cloud, and will be regulated as such.
So What? Cross-border AI deals are now political events. If you’re building core models, agents, or foundational tooling in a jurisdiction with active industrial policy, your exit and partnership options are no longer just about price and fit, they’re about national strategy. That slows down deals, increases uncertainty, and pushes both buyers and founders toward parallel domestic build strategies.
The Risk: If your cap table or leadership is heavily cross-border, especially US–China or EU–China, you may find yourself in the middle of a regulatory tug-of-war. And if your strategy assumes “we’ll just sell to a global platform,” you may discover that option is either delayed or blocked.
Action: • Audit your cross-border exposure: founders, key employees, IP location, data residency, and major customers. • If you’re building core AI in a geopolitically sensitive domain, engage local counsel early to understand FDI and export control implications for future funding and exits. • As a buyer, assume longer timelines and higher execution risk for acquisitions involving sensitive AI assets, build organic alternatives in parallel.
An EQT and McKinsey study found that between 2014 and 2025, European tech companies with a combined value of roughly €1.2T (~$1.4T) listed abroad or were acquired by foreign buyers, per Techmeme / Bloomberg. This is value leaving European public markets and control structures.
The Bet: Europe will continue to be a producer of high-value tech assets, including AI, but much of the upside will be captured elsewhere unless structures change.
So What? If you’re building in Europe, the default path is global: raise from global funds, sell to global buyers, list on non-European exchanges. That brings capital and reach, but it also means European ecosystems function as feeders into larger platforms. For AI and infra, that has sovereignty implications, who controls the models, data, and infra built on European soil.
The Risk: If policymakers respond with heavy-handed restrictions instead of competitive capital and listing environments, founders will route around them, by incorporating elsewhere or moving IP. And if you’re an operator assuming stable European ownership of your critical vendors, you may wake up to find them controlled by foreign entities with different priorities.
Action: • As a European founder, design your governance and IP structure with global capital in mind from day one, but be explicit about what you’re willing to sell and where you want to list. • As a European enterprise buyer, map your critical vendors’ ownership and likely exit paths, and consider diversifying where control risk is high. • If you’re a policymaker or ecosystem leader, focus on making local listings and growth capital genuinely competitive, not just on restricting outbound deals.
AI Supremacy outlined the geopolitical chokepoints of AI, from helium to DRAM to HBM, arguing that obscure materials and memory supply are as strategic as GPUs, per AI Supremacy. The piece frames AI as dependent on a broader commodity stack.
The Bet: Control over the full AI materials and memory supply chain will be as important as control over GPU design and fabrication.
So What? Your AI infra risk map is incomplete if it only tracks GPUs and cloud regions. Helium for chip manufacturing, advanced memory for training and inference, and even specialty gases become potential single points of failure. For operators, that means infra planning needs a commodity lens, not just a cloud procurement lens.
The Risk: If you assume your cloud provider will abstract away all supply risk, you’re exposed to systemic shocks, export controls, natural disasters, or industrial accidents, that ripple through multiple layers at once. And if you’re building your own infra, you may be underestimating lead times and price volatility for non-obvious inputs.
Action: • Ask your infra and cloud vendors how they’re managing non-GPU chokepoints, memory, gases, specialty materials, and what that means for your SLAs. • For large, long-lived AI deployments, build scenario plans that include supply shocks outside of GPUs, and identify which workloads you’d shed or degrade first. • If you’re in a position to influence policy or industry groups, push for more transparency and diversification in AI-critical materials supply chains.

ASSISTANTS / SURFACES
Assistants are becoming first-class products and channels
Reports say Siri will become a standalone app in iOS 27, turning the assistant into its own product surface with dedicated engagement and monetization levers, per Mashable. This shifts Siri from a system feature to an app with its own lifecycle.
The Bet: The assistant is not just a voice shortcut, it’s a primary interface that can be measured, iterated, and monetized like any other app.
So What? For anyone building on iOS, Siri is about to become a channel, with its own integration points, ranking dynamics, and potentially its own “app store” logic. That changes how you think about distribution: instead of just pushing users into your app, you’ll be competing to be the action Siri chooses when a user asks for something in your domain.
The Risk: If you ignore this shift, you risk being disintermediated, Siri handles the user’s intent and routes it to a competitor or to Apple-native services. And if you over-index on Siri without understanding its policies and ranking, you could build dependency on a surface you don’t control.
Action: • Assign someone on product or BD to own “assistant surfaces” across platforms, Siri, ChatGPT, Gemini, etc. Treat them as channels, not features. • Start mapping your core user intents to natural language queries, and design how you’d want Siri to fulfill them. That informs your future integration strategy. • Watch for early documentation or beta programs around Siri-as-app, get in early to understand how ranking, attribution, and monetization will work.
OpenAI hired Kiran Mani, CEO of Indian streaming platform JioStar, to lead its Asia-Pacific operations, reporting to CSO Jason Kwon, per Techmeme / Bloomberg. Mani brings India-scale consumer and monetization experience.
The Bet: The assistant in APAC is a distribution and monetization business, not just a research or enterprise sales outpost.
So What? This is a clear signal that OpenAI sees APAC, and especially India, as a massive consumer assistant market with its own go-to-market, partnerships, and monetization logic. For enterprise vendors, that means your AI channel conversations in the region will increasingly run through or alongside assistant platforms, not just through traditional SaaS and SI routes.
The Risk: If you’re an enterprise or ISV in APAC and you ignore the assistant as a distribution layer, you risk being sidelined as users and developers default to assistant-native workflows. Conversely, if you over-partner without clarity on data, branding, and economics, you could become a thin feature inside someone else’s assistant.
Action: • If you operate in APAC, map where assistant platforms, ChatGPT, Gemini, local players, intersect with your customer journeys today. • Start exploratory conversations with assistant platform teams about integration, co-selling, and data boundaries, before their playbook hardens. • Design at least one “assistant-native” experience for your product, something that lives primarily in an assistant, not in your own UI, and test it with a small user segment.
IN PRACTICE
The pattern across these rails is simple: constraints are becoming product features, and surfaces are becoming channels.
We’re working with teams who are re-architecting around three principles:
• Own your bottlenecks. If compute, data, or safety are existential constraints, they belong on your leadership agenda, with explicit owners, budgets, and metrics. • Treat assistants and agents as distribution, not just UX. Where your users start their intent, Siri, ChatGPT, internal copilots, is where your product needs to show up. • Align capital with control. If infra and AI are core to your value, renting everything from hyperscalers and model vendors is a strategic choice, not a default.
For the full breakdown, reach out for a Field Report.
CONTRARIAN SIGNAL
The real AI moat isn’t models, it’s constraint management
The dominant narrative is still about model quality and feature velocity. Bigger models, more modalities, more assistants. The implicit assumption: if you can build it and users want it, you should ship it.
Yesterday’s moves say the opposite. OpenAI is killing products to protect compute. CPUs and memory, not just GPUs, are hitting supply ceilings. Google is investing in extreme compression to do more with less. Databricks is collapsing security into the lakehouse to avoid paying the “data gravity tax” twice.
The organizations that win this cycle won’t be the ones with the flashiest demos. They’ll be the ones that treat constraints, compute, capital, regulation, safety, as first-class design inputs and build products, pricing, and org structures around them.
The Takeaway: Stop planning as if constraints are temporary headwinds. Start designing as if they’re the terrain, and your job is to own the high ground.
THE QUESTION FOR TODAY
Your vendors are making hard tradeoffs based on their GPU budgets, not your roadmap. Your infra is exposed to chokepoints you don’t track, CPUs, memory, materials, regulation. Your security and safety surfaces are becoming data and legal liabilities, not just tools. Your users are shifting intent to assistants and agents you don’t fully control.
Are you still building as if you own the platform, or as if you’re a tenant in someone else’s constrained stack?
⸻
See exactly how this impacts your specific industry and function. Upgrade to PRO to get bespoke tactical breakdowns generated instantly for your operating model.
Go deeper with the Weekly Signal
This is the daily take. The Weekly goes further — full strategic analysis across 8–10 sections, each with a signal read and operator action items. Source panel included.
Sign up free → then upgrade