The AI data center boom is moving closer to cities — and this Texas developer just raised $2 billion to bet on it
THE SO WHAT
Inference is dragging 10–50 MW blocks of AI compute into metro areas — latency and data gravity are beating cheap land. If you're building AI products, your edge is now colo selection and network topology, not just which model you call.
READ THE SOURCE
MORE FROM THE WIRE
 Deep & Emerging Tech
Deep & Emerging TechWhere Utah’s experiment with AI doctors is headed next
Utah letting AI systems prescribe meds is a regulatory jailbreak—care delivery is being rewritten at the state level, not by federal consensus. If you build in healthcare, route your go-to-market through permissive jurisdictions first and design your stack for a patchwork, not a single rulebook.
 Deep & Emerging Tech
Deep & Emerging TechExplaining AMD gear modes and why they’re important for intensive workloads
AMD’s Gear 1 vs Gear 2 tradeoff—latency versus bandwidth—pushes AI infra teams to tune memory like they tune models. If you’re running intensive inference or training on AMD, stop treating BIOS settings as static; there’s free performance sitting in your memory controller.
 Deep & Emerging Tech
Deep & Emerging Tech'88% Confident 90% Misled': Government & critical infrastructure leaders fundamentally misunderstand the security of the apps they use
When 88% of leaders are confident and 90% misunderstand encryption, your risk isn’t just attackers—it’s decision-makers approving insecure stacks. If you touch critical infrastructure, stop selling “secure by default” and start running exec‑level security education, or your own customers will be your biggest vulnerability.
 Deep & Emerging Tech
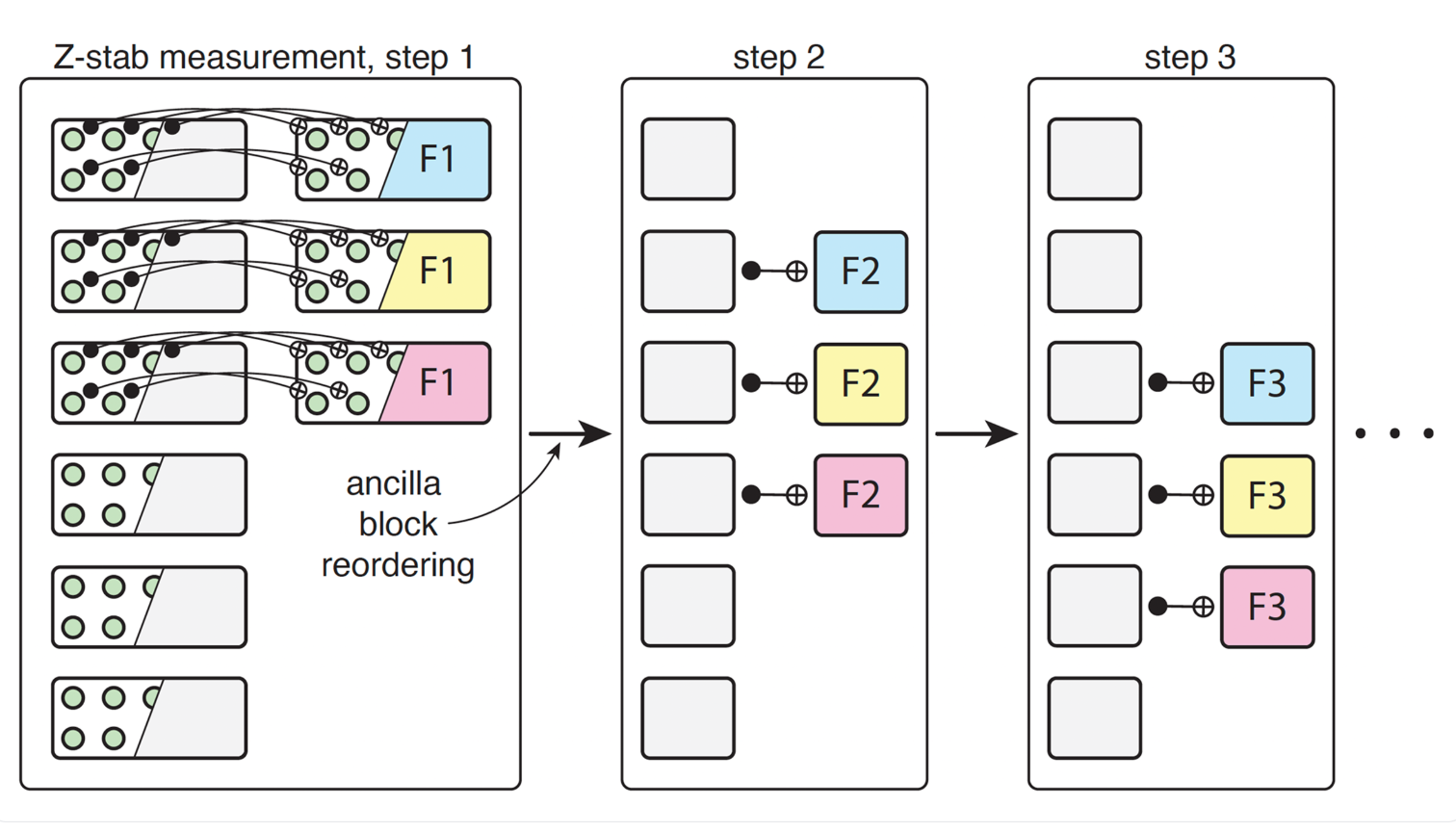
Deep & Emerging TechQuEra-led Study Points to Ultra-High-Rate Quantum Error Correction Moving Closer to Practical Hardware
Quantum error-correcting codes with >50% encoding rates and low logical error on neutral atoms shrink the overhead tax that’s kept quantum in the lab. If you’re in HPC, cryptography, or materials, you now need a 5–10 year quantum threat/opportunity model — not a 20-year shrug.